Wat
In this article I will detail the thought process and implementation of an automated build and deployment pipeline that I wrote to reduce the time taken to get feedback for code changes I make to my code bases.
The bulk of this code is written in Go and Bash. It’s a very hacky implementation but was extremely fun to write and use.
Disclaimer: This post is quite code heavy, but I try to highlight the thought-process behind the code.
You can find the code for this entire post here cicdexample
This is a quick GIF of what we're going to build:

That sounds cool, but why?
Feedback is important
The most important part for me when writing any sort of code is how fast I can get feedback.
Earlier this year I started learning Go in my spare time and whilst learning, I wanted to Dockerize my application code (I was writing my first web app in Go) and eventually host it on Heroku.
So this is what I was doing for a few days:

In total, it was taking me ~ 10 minutes to verify new functionality in a'production' environment.No exactly bad turnaround time when you’re working on something for your day-job, but for a pet project it wasn’t really that fun.
An added downside to the above pipeline is that it is really hard to test functionality when I don't have a consistent internet connection, which happens rather often. So I started to think about alternatives.
I wanted to have minimal latency between ctrl-s and testing the change - kind of like this diagram:

Environment consistency trade-off
I realised that testing on Heroku wasn’t a hard requirement for my development process. But I did want some resemblance to my 'production' environment in my test environment.
I started to sketch out a simple CI/CD pipeline I could run on my laptop that would allow me to test my application running in Docker on similar cloud infrastructure.
As an aside, I kind of knew that I was probably going to write something that already exists, but I also knew that it would be a fun exercise and learning experience.
A simple start
What do you need to have?
- Go (any version will do for this article)
- Some Bash knowledge and a Unix terminal
- Minikube
- Kubectl
- Docker
- An IDE or Text Editor (I interchangeably use Vim and VSCode throughout this article)
- Linux (Ubuntu 18.04 LTS is the distro I am using)
Where do we start?
I have some experience working with build tools like Jenkins and I also have some experience with running an automated build pipeline tied to an automatic deployment tool.
So using the ideas and context I had from those tools. I started simply, I ignored Heroku for the moment and wrote a simple Shell script that would build my go code base, and then based on a command line argument, build and tag the Docker image(s).
I extended the Shell script to include a kubectl command to deploy to Minikube after building a docker image.
I realised that now that I had this Shell script, I had in essence created a deployment and build job for my application. So I started putting together a Go app to automate the running of this script based on a trigger.
How exactly did you do that?
To illustrate how I did this without complicating this post with excessive technical detail, I’ve created a little checklist to follow, which this article expands upon:
a. Create a small Go application that serves a HTML pageb. Dockerize it!c. Write a simple Bash script that builds the docker imaged. Push the docker image into Minikube and see it rune. Write a small command line tool that runs the script automatically
Creating the test application
Let’s create an example Go application that starts a simple file server and serves a simple HTTP page (that uses Bulma CSS to make it look a bit better) on ‘/’
The web server looks like this:
package main
import (
"log"
"net/http"
"os"
)
func main() {
// for heroku since we have to use the assigned port for the app
port := os.Getenv("PORT")
if port == "" {
// if we are running on minikube or just running the bin
defaultPort := "3000"
log.Println("no env var set for port, defaulting to " + defaultPort)
// serve the contents of the static folder on /
http.Handle("/", http.FileServer(http.Dir("./static")))
http.ListenAndServe(":" + defaultPort, nil)
} else {
http.Handle("/", http.FileServer(http.Dir("./static")))
log.Println("starting server on port " + port)
http.ListenAndServe(":" + port, nil)
}
}
The html file in /static is quite simply:
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>CI/CD Example</title>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.8.0/css/bulma.min.css">
</head>
<body>
<div style="text-align: center" class="container">
<h1 class="title is-1">Example CI/CD Stuff</h1>
<p>Changes should make this automatically redeploy to our local test environment</p>
</div>
</body>
</html>
Great, now if we build (go build) this Go App and run it, we should be able to see the following at localhost:3000

Containerisation
We now have an app, which is really cool and does a whole bunch of stuff (nothing) but that is beside the point. We’re focused on how to get this little guy building himself. First things first, we need to Dockerize it.
If you don’t have Docker installed, check out their docs here (https://docs.docker.com/install/)
Let's create the following simple 2-stage Dockerfile:
# Stage 1
FROM golang:alpine as builder
RUN apk update && apk add --no-cache git
RUN mkdir /build
ADD . /build/
WORKDIR /build
RUN go get -d -v
RUN go build -o cicdexample .
# Stage 2
FROM alpine
RUN adduser -S -D -H -h /app appuser
USER appuser
COPY --from=builder /build/ /app/
WORKDIR /app
CMD ["./cicdexample"]
This Dockerfile first creates a builder image with the entire contents of the local directory copied into a directory called /build on the image. It then fetches the dependencies for our little app, and builds it - producing a binary called cicdexample
The second stage actually creates the image we will ultimately run. We use the base Alpine image and create a user called appuser that uses a directory called /app as it’s home directory.We then copy the contents of the /build directory from the builder image into the /app directory on the Alpine image, set the working directory to /app and run the Go binary that we just copied. It’s important to note that we copy the entire /build directory contents since we need the static resources directory that is not part of the Go binary.
Once we’ve created the Dockerfile and can successfully rundocker build -t example:test . which produces (output is slightly trimmed):
Sending build context to Docker daemon 7.638MB ... Successfully built 561ee4597a93 Successfully tagged example:test
we're ready to move on.
Bashing things into shape
Next up we need a script to automate the process of building this Docker image for us. But we don’t just want to build an image with a script, we want to create a feedback loop using go build so that we don’t waste time setting up a Docker image when our code doesn’t even compile.
We don’t technically have to flag success from the result of go build, but rather have the error output redirected to a file, which we can then check for ANY content, and signal failure if there is anything in stderr as a result of go build
The logical steps for this script are best represented graphically:
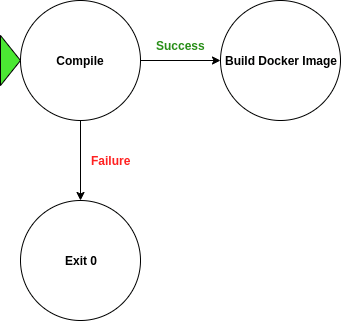
The script is as follows (with a nice timestamps and command line output included):
#!/bin/bash
# Timestamp Function
timestamp() {
date +"%T"
}
# Temporary file for stderr redirects
tmpfile=$(mktemp)
# Go build
build () {
echo "⏲️ $(timestamp): started build script..."
echo "🏗️ $(timestamp): building cicdexample"
go build 2>tmpfile
if [ -s tmpfile ]; then
cat tmpfile
echo "❌ $(timestamp): compilation error, exiting"
rm tmpfile
exit 0
fi
}
# Deploy to Minikube using kubectl
deploy() {
echo "🌧️ $(timestamp): deploying to Minikube"
kubectl apply -f deploy.yml
}
# Orchestrate
echo "🤖 Welcome to the Builder v0.2, written by github.com/cishiv"
if [[ $1 = "build" ]]; then
if [[ $2 = "docker" ]]; then
build
buildDocker
echo "✔️ $(timestamp): complete."
echo "👋 $(timestamp): exiting..."
elif [[ $2 = "bin" ]]; then
build
echo "✔️ $(timestamp): complete."
echo "👋 $(timestamp): exiting..."
else
echo "🤔 $(timestamp): missing build argument"
fi
else
if [[ $1 = "--help" ]]; then
echo "build - start a build to produce artifacts"
echo " docker - produces docker images"
echo " bin - produces executable binaries"
else
echo "🤔 $(timestamp): no arguments passed, type --help for a list of arguments"
fi
fi
Running it, with the varying arguments, gives us the following:
./build build bin (compilation failure)
🤖 Welcome to the Builder builder v0.2, written by github.com/cishiv
⏲️ 16:40:47: started build script...
🏗️ 16:40:47: building cicdexample
# _/home/shiv/Work/dev/go/cicdexample
./main.go:25:1: syntax error: non-declaration statement outside function body
❌ 16:40:47: compilation error, exiting
./build build docker (slightly trimmed output)
🤖 Welcome to the Builder builder v0.2, written by github.com/cishiv
⏲️ 16:40:05: started build script...
🏗️ 16:40:05: building cicdexample
🐋 16:40:06: building image example:test
Sending build context to Docker daemon 7.639MB
...
Successfully tagged example:test
✔️ 16:40:06: complete.
👋 16:40:06: exiting...
This seems reasonable, we can compile our code and build a docker image with one command.
Before we head to the next step, let's have a look at our checklist so far:
a. Create a small Go App that serves a HTML page ✔️b. Dockerize it! ✔️c. Write a simple Bash script that builds the docker image ✔️d. Push the docker image into Minikube and see it rune. Write a small command line tool that runs the script automatically
Minikube-ing
We finally have some sort of automation for our build pipeline, but it doesn't really give us a way to test our application yet.
Enter Minikube to save the day (sort of).
We want our testing pipeline to be as follows:

If you don’t have Minikube installed you can check out the docs here (https://kubernetes.io/docs/tasks/tools/install-minikube/) on how to get it up and running.
You will also need to grab kubectl.
Once Minikube is installed, it is as simple as running minikube start to start up a single node cluster.
The next step is setting up a Kubernetes deployment for our app, that we can push into the Minikube cluster.
Since this is not an article about Kubernetes, I will keep this step short. We want to have a deploy.yml file where we can tell Kubernetes to create a deployment and a service for our application. It would be nicer to have separate files for creating the deployment and service, but for this example, we’ll just recreate both of them every time we want to redeploy.
So we need the following file.
apiVersion: apps/v1
kind: Deployment
metadata:
name: example
spec:
selector:
matchLabels:
app: example
tier: example
track: stable
template:
metadata:
labels:
app: example
tier: example
track: stable
spec:
containers:
- name: example
image: "example:test"
ports:
- name: http
containerPort: 3000
---
apiVersion: v1
kind: Service
metadata:
name: example
spec:
type: NodePort
selector:
app: example
tier: example
ports:
- protocol: TCP
port: 3000
targetPort: http
nodePort: 30000
We tell kubernetes to create a service called example that is exposed on NodePort 30000 (so that we can access it via a URL that doesn't change every time we recreate the service) , with an application running on port 3000 in the container.
At this point, because we have specified a NodePort in our deployment descriptor we should be able to simply refresh our web page, and see our changes.
To get the application deployed into the cluster, run the following command in the terminal:
./build build docker && kubectl apply -f deploy.yml
The application should now be live on the Minikube cluster and be exposed on a NodePort.
To get the URL for the application, run this command:
minikube service example --url
You should get a URL similar to this:
http://10.0.0.101:30000
example is the service name we specified in our deploy.yml file.
If we navigate to our URL, we should see our app.
We can now test our pipeline for the first time.
Make a code change to index.html and run:
./build build docker && kubectl apply -f deploy.yml
You might find that this doesn't actually work yet. The kubectl command outputs:
deployment.apps/example unchanged service/example unchanged
And rightly so, since we don't tag our Docker image differently each time we create it - Kubernetes doesn't actually recognise that our code has changed. A quick hack to remedy this, since we're testing locally, is to amend our command to the following:
./build build docker && kubectl delete deployment example && kubectl delete service example && kubectl apply -f deploy.yml
This allows us to cleanly recreate the service and deployment every time we re-run the script. It's important to note that this is very much a hack, and a better way to do this would be to tag the Docker images differently each time they are produced, and update the deploy.yml file with the correct Docker image tag.
So running:
./build build docker && kubectl delete deployment example && kubectl delete service example && kubectl apply -f deploy.yml
Will allow us to see the change we made to our HTML.
This seems reasonable, however to clean it up a bit, let's add the additional kubectl commands to our Bash script.
It is simple enough to do by adding the following function, and making a change to the conditional logic slightly, allowing for a deploy parameter to be passed to the ./build build ... command:
Function:
# Deploy to Minikube using kubectl
deploy() {
echo "🌧️ $(timestamp): deploying to Minikube"
kubectl delete deployment example
kubectl delete service example
kubectl apply -f deploy.yml
}
Conditional logic:
if [[ $1 = "build" ]]; then
if [[ $2 = "docker" ]]; then
if [[ $3 = "deploy" ]]; then
build
buildDocker
deploy
else
build
buildDocker
fi
echo "✔️ $(timestamp): complete."
echo "👋 $(timestamp): exiting..."
We can now run:./build build docker deployto quite easily drive code changes all the way from compilation to deployment! (with a turn-around time of ~1s)
The Final Act: True Automation
Finally, we want to wrap the Bash script we have created into a purpose built Go application that automates this process.
We have to decide on a trigger for our build pipeline. There are 2 options at this point, which are:
- Builds are triggered on a combination of time elapsed and file changes.
- Builds are triggered on commits into a git repository
To illustrate the concept without much technical overhead, we will go with the first option
This is essentially what we want to write:

I won't paste the entire source code here, however I will discuss a few key points regarding it (the full code can be found here)
We need to address 5 problems:
- What sort of hashes are we going to use for files?
- How often should the hash recalculation be done?
- How do we set up polling on an interval?
- How do we run our script in the context of a Go application?
- What race conditions are there?
The first problem is solved quite succinctly in Go, we can calculate a sha256 hash for a file with just the following code snippet:
func CalculateHash(absoluteFilePath string) string {
f, err := os.Open(absoluteFilePath)
HandleError(err)
defer f.Close()
h := sha256.New()
if _, err := io.Copy(h, f); err != nil {
log.Fatal(err)
}
return hex.EncodeToString(h.Sum(nil))
}
The second problem has a non-trivial answer and it specific to your use case, however it should be reasonable enough to recalculate hashes every 15 seconds or so - this means that we should have automated deployments running every 15 seconds if there was a code change in that window.
I ran a few benchmarks on the actual time taken to run a build in the Go application so that we could make an educated guess on how often to poll for file changes.
The snippet I used to run the benchmark is as follows:
func stopwatch(start time.Time, name string) {
elapsed := time.Since(start)
log.Printf("%s took %s", name, elapsed)
}
Simply add defer stopwatch(time.Now(), "benchmark") at the top of the function you want to benchmark!
After the benchmark I estimated that we need to allow for 7 seconds for a past build to complete, and 8 seconds of overhead for the unexpected. Which gives us a total of 15 seconds.
Problem number 3 is solved by defining the following function and using it like illustrated:
package main
import (
"fmt"
"time"
)
func main() {
go DoEvery(10*time.Second, f, "test")
for {}
}
func DoEvery(d time.Duration, f func(time.Time, string), action string) {
for x := range time.Tick(d) {
f(x, action)
}
}
func f(t time.Time, action string) {
fmt.Println(action)
}
We simply create a function that will be invoked every X seconds.
The 4th problem also has a rather simple and effective solution in Go, we can define an action string and run it using the os/exec package in Go.
package main
import (
"bytes"
"log"
"os/exec"
)
func main() {
runAction("./build build docker deploy")
}
func runAction(action string) {
log.Println("Taking action, running: " + action)
cmd := exec.Command("/bin/sh", "-c", action)
var outb, errb bytes.Buffer
cmd.Stdout = &outb
cmd.Stderr = &errb
err := cmd.Run()
if err != nil {
log.Printf("error")
}
log.Println(outb.String())
log.Println(errb.String())`
The last problem is an important one, one glaring race condition is that if we monitor the hashes for ALL the files in a directory, then we will most likely get caught in some sort of recursive build loop, since we are actively changing the files we monitor (by producing a binary). We can borrow a concept from `git` here, and implement a `whitelist`, that is, a list of files to ignore in our hash calculation. Something to this affect,
`var whiteList []string
func CreateWhiteList() {
file, err := os.Open("./.ignore")
if err != nil {
log.Println("no .ignore file found, race condition will ensue if jobs edit files -- will not create whitelist")
} else {
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
log.Println(scanner.Text())
whiteList = append(whiteList, scanner.Text())
}
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
}
}
Combining the solutions to these problems, we're able to produce this)
Building the builder withgo build -o pipeline will result in a binary called pipeline.
We can then move this binary into our working directory. We also need to create an ignore file in our working directory to ignore the binary produced by the builder for our application.
The ignore file is simply:
pipeline cicdexample
We ignore .git programatically, since it's never something we want to include.
We can finally run our builder
./pipeline
Making a change to the index.html of our app, should kick off an automated build and redeployment, exactly as we set out to do.
As you can see from this output:
shiv@shiv-Lenovo-ideapad-310-15IKB:~/Work/dev/go/cicdexample$ sudo ./pipeline
2019/12/24 18:23:42 map[]
2019/12/24 18:23:42 creating whitelist
2019/12/24 18:23:42 pipeline
2019/12/24 18:23:42 cicdexample
2019/12/24 18:23:42 builder
2019/12/24 18:23:42 building registry
2019/12/24 18:23:42 starting directory scan
2019/12/24 18:23:42 pipeline is whitelisted, not adding to registry
2019/12/24 18:23:42 computing hashes & creating map entries
2019/12/24 18:23:57 verifying hashes
2019/12/24 18:24:12 verifying hashes
2019/12/24 18:24:12 ./static/index.html old hashbebc0fe5b73e2217e1e61def2978c4d65b0ffc15ce2d4f36cf6ab6ca1b519c17new hash16af318df74a774939db922bcb4458a695b9a38ecf28f9ea573b91680771eb3achanged detected - updating hash, action required
2019/12/24 18:24:12 Taking action, running: ./build build docker deploy
2019/12/24 18:24:20 🤖 Welcome to the Builder builder v0.2, written by github.com/cishiv
⏲️ 18:24:12: started build script...
🏗️ 18:24:12: building cicdexample
🐋 18:24:13: building image example:test
Sending build context to Docker daemon 10.11MB
...
Successfully tagged example:test
🌧️ 18:24:19: deploying to Minikube
deployment.apps "example" deleted
service "example" deleted
deployment.apps/example created
service/example created
✔️ 18:24:20: complete.
👋 18:24:20: exiting...
2019/12/24 18:24:20
2019/12/24 18:24:20 --------------------------------------------------------------------------------
2019/12/24 18:24:27 verifying hashes
That's it! We're done. We've successfully written, a useful - albeit simple CI/CD pipeline to improve our development process.
What are the takeaways from this experience?
Tips
It might be tempting to use a pre-existing solution for this kind of pipeline, but my recommendation is that if you have the time and energy to write a small solution to a problem you’ve encountered, you definitely should. It forces you to think about how your application(s) work in a production setting as well as how your development process can be improved. It is also a lot of fun.
Extensions
There are many possible extensions to this project, some of which I want to tackle soon, I've listed some of the more interesting ones here:
- Allow for the creation of build scripts via the builder app
- Build from VCS (i.e git clone a repo and build it based on a job description)
- A UI for this build pipeline
- Run the builder app in Docker on Minikube itself
- Host the builder app on a cloud platform and have configurable deployments and builds
- Let users create
.jsonjob files for builds - Multi-language support
Caveats
This kind of quick and dirty pipeline isn’t better than a pre-existing solution, but it is a lot more fun to use, since I can quickly make changes to it based on a need I may have.
I am relatively new to Go, Kubernetes and Docker. So the style I used may not be best practise, but it does work for me.
Usage Examples
I am currently using a similar pipeline to automate the deployment of a project that I am working on called Crtx (http://crtx.xyz/) - into a test environment as I write code. It is primarily a Go code base with multiple apps that are deployed continuously to a Minikube cluster. This pipeline makes testing data flows between applications much easier.
Closing Remarks
This is the first time I’ve written a technical article and would love to hear feedback on the approach I took, as well as on the actual content!
I plan to write more about the tools I use and build, so if you enjoyed reading this please let me know!
You can give me feedback on Twitter or right here in the comments ✍️